




Das herkömmliche Telefonnetz überträgt Sprache per Leitungsvermittlung und die erforderliche Breitbandübertragung beträgt 64 kbit/s. Das sogenannte VoIP basiert auf einem IP-Paketvermittlungsnetzwerk als Übertragungsplattform. Das analoge Sprachsignal wird komprimiert, verpackt und einer Reihe spezieller Verarbeitungsschritte unterzogen, sodass es das verbindungslose UDP-Protokoll zur Übertragung verwenden kann.
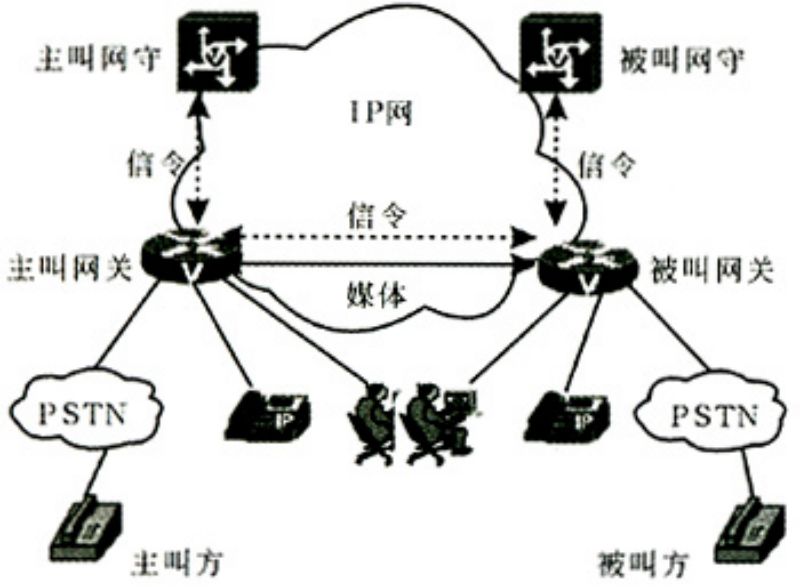
Zur Übertragung von Sprachsignalen in einem IP-Netzwerk sind mehrere Elemente und Funktionen erforderlich. Die einfachste Form des Netzwerks besteht aus zwei oder mehr Geräten mit VoIP-Funktionen, die über ein IP-Netzwerk verbunden sind.
1、 Voice-to-Data-CoVersion
Das Sprachsignal ist eine analoge Wellenform, die Sprache über IP überträgt, unabhängig davon, ob es sich um eine Echtzeitanwendung oder eine Nicht-Echtzeitanwendung handelt. Erstens sollte das Sprachsignal in analoge Daten umgewandelt werden, d. h. das analoge Sprachsignal sollte Um 8 oder 6 Bits quantisiert und dann an den Pufferspeicherbereich gesendet werden, kann die Größe des Puffers entsprechend ausgewählt werdenan die Verzögerungs- und Codierungsanforderungen. Viele Encoder mit niedriger Bitrate basieren auf der Frame-Codierung.
Typische Rahmenlängen liegen zwischen 10 und 30 ms. Unter Berücksichtigung der Übertragungskosten besteht das Interspeech-Paket normalerweise aus 60, 120 oder 240 ms Sprachdaten. Eine Digitalisierung ist möglichdurch die Verwendung verschiedener Sprachcodierungsschemata, wobei das wichtigste ITU-T G.711 ist. Der Sprachencoder am Quellziel muss denselben Algorithmus implementieren, damit das Sprachgerät am Ziel das analoge Sprachsignal wiederherstellen kann.
2, die ursprünglichen Daten zu tdie IP-Konvertierung
Einmal das Sprachzeichenal digital kodiert ist, besteht der nächste Schritt darin, das Sprachpaket mit einer bestimmten Rahmenlänge zu komprimieren und zu kodieren. Die meisten Encoder haben eine bestimmte Framelänge. Wenn ein Encoder einen 15-ms-Frame verwendet, wird das 60-ms-Paket aus dem ersten in vier Frames unterteilt und der Reihe nach codiert. Jeder Frame verfügt über 120 Sprachsamples (Abtastrate 8 kHz). Nach der Kodierung werden die vier komprimierten Frames zu einem komprimierten Sprachpaket synthetisiert und an den Netzwerkprozessor gesendet. Der Netzwerkprozessor fügt der Stimme Paketheader, Zeitstempel und andere Informationen hinzu und sendet sie über das Netzwerk an den anderen Endpunkt.
Das Sprachnetzwerk stellt lediglich physische Verbindungen (eine Leitung) zwischen den Kommunikationsendpunkten hers und überträgt die kodierten Signale zwischen den Endpunkten. Im Gegensatz zu leitungsvermittelten Netzwerken bilden IP-Netzwerke keine Verbindungen; Stattdessen müssen Daten in Datagrammen oder Paketen variabler Länge platziert werden, die dann jeweils mit Adressierungs- und Steuerinformationen über das Netzwerk gesendet und von Station zu Station an ihr Ziel weitergeleitet werden
3. Übertragen
In diesem Kanal wird davon ausgegangen, dass das gesamte Netzwerk ein Sprachpaket vom Eingang empfängt und es dann innerhalb einer bestimmten Zeit (t) an den Netzwerkausgang weiterleitet. Der Wert kann in einem gewissen Bereich schwanken, was auf Jitter bei der Netzwerkübertragung zurückzuführen ist.
Peers im Netzwerk prüfen die Adressinformationen, die jedem IP-Paket beigefügt sind, und verwenden diese Informationen, um das Datagramm an die nächste Station auf dem Weg zu seinem Ziel weiterzuleiten. Ein NetzDer Arbeitslink kann eine beliebige Topologie oder Zugriffsmethode sein, die IP-Datenflüsse unterstützt.
4、 IP-Paket- dateine Konvertierung
Das Ziel-VoIP-Gerät empfängt diese IP-Daten und beginnt mit der Verarbeitung. Die Netzwerkebene stellt einen Puffer variabler Länge bereit, der zur Regulierung des vom Netzwerk erzeugten Jitters verwendet wird. Der Puffer kannPlatz für viele Sprachpakete und Benutzer können die Größe des Puffers wählen. Kleine Puffer erzeugen kleinere Verzögerungen, können aber großen Jitter nicht regulieren. Zweitens entpackt der Decoder das codierte Sprachpaket, um ein neues Sprachpaket zu erzeugen. Dieses Modul kann auch per Frame betrieben werden, der genau die gleiche Länge wie der Decoder hat.
Wenn die Rahmenlänge 15 ms beträgt, werden die 60 ms langen Sprachpakete in 4 Rahmen aufgeteilt und dann in einen 60 ms langen Sprachdatenstrom dekodiert und in den Dekodierungspuffer gesendet. Während des ProBei der Verarbeitung des Datagramms werden die Adressierungs- und Steuerinformationen entfernt und die ursprünglichen Rohdaten bleiben erhalten, die dann dem Decoder bereitgestellt werden.
5、 Digitaler Sprachkonvertersion auf analoge Stimme
Der Wiedergabetreiber entnimmt die Sprachabtastpunkte (480) im Puffer, sendet sie an die Soundkarte und sendet sie mit einer vorgegebenen Frequenz (z. B. 8 kHz) über den Lautsprecher. Kurz gesagt, die Übertragung von Sprachsignalen über IP-Netzwerke erfolgt durch die Umwandlung von analogen Signalen in digitale Signale, die KapselungUmwandlung digitaler Sprache in IP-Pakete, Übertragung von IP-Paketen über das Netzwerk, Entpacken von IP-Paketen und Wiederherstellung digitaler Sprache in analoge Signale.
VOIP ist eines unserer GeschäftsfelderONUSerien-Netzwerkprodukte und die relevanten Hot-Netzwerkprodukte unseres Unternehmens decken verschiedene Arten abONUSerienprodukte, einschließlich ACONU/ KommunikationONU/ intelligentONU/ KastenONU/ doppelte PON-PortsONUusw. Das ObigeONUSerienprodukte können für die Netzwerkanforderungen verschiedener Szenarien eingesetzt werden. Willkommen, um ein detaillierteres technisches Verständnis der Produkte zu erhalten.
